こんにちは。ラクスルのプロダクト基盤部のEM兼PdMを担当している安尾(@yusuke_yasuo)です。
2023年8月にラクスルに入社して以来、ラクスルにおける決済基盤の構築を担当しています。
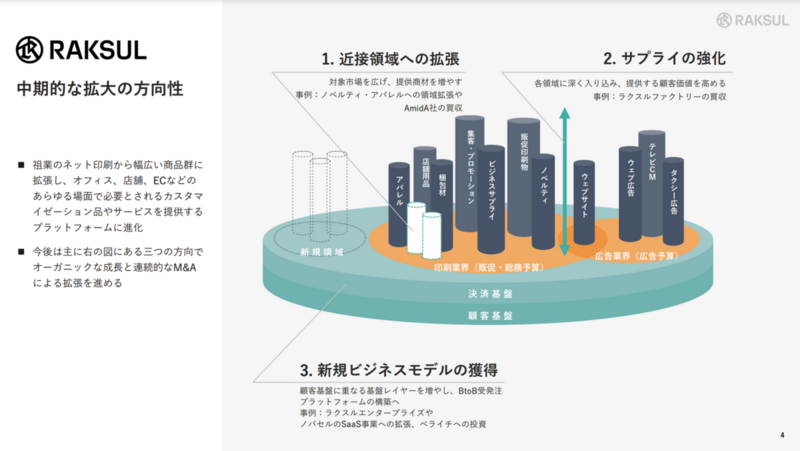 引用:2024年7月期第2四半期 決算説明会資料
引用:2024年7月期第2四半期 決算説明会資料
EM候補として入社して10月に正式にEMとなり今月で半年になるため、一度振り返りをしてみようと思います。
目指すEM像
振り返る前に私が目指すEM像について簡単に紹介したいと思います。
一言で言うと、こちらの記事で書かれているような「強めのEM」が私が目指すEM像です。
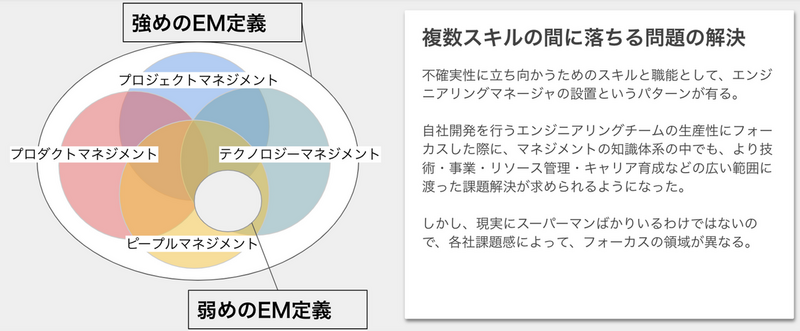 引用:エンジニアリングマネージャ/プロダクトマネージャのための知識体系と読書ガイド
引用:エンジニアリングマネージャ/プロダクトマネージャのための知識体系と読書ガイド
会社によってはピープルマネージメントやテクノロジーマネージメントを行うのがEMというところもあるかもしれませんが、経験上チームとしての成果を最大化するためにはプロダクトマネージメントやプロジェクトマネージメントのスキルが重要になる場面も多いと感じており、その時々でチームの成果を最大化するために最も効果的なレバーを見つけてそれを引くことができるようなEMになれればと考えています。
ちなみに、ラクスルにおける理想のEM像もまさにこの「強めのEM」というイメージで、会社における理想のEM像と私の目指すEM像の一致度はとても高いと感じています。
ラクスルはマイクロサービスで動いており、異なる目的や特性を持ったシステムが存在し、所属エンジニアのスキルセットも当然チームによって様々なので、ラクスルのEMは各チームの状況にあわせてレバレッジが効くスキルを発揮することで成果を上げていると感じています。
半年間を振り返って
一言で言うと、とても充実した半年が過ごせたと思っています。
ちょうど大きなプロジェクトが始まるタイミングに入社した幸運もありますが、決済基盤構築プロジェクトの計画から実行まで、大きな裁量を持ってチャレンジできていることが一番の要因です。
プロジェクトを「なぜやるか」が明確になっている状態で参画し、「何をつくるか」「どうやってつくるか」「どういう体制でつくるか」などについては自分で主体的に考えられる環境だったため、これまで経験したことがないような多くのチャレンジをすることができました。
本記事では、印象に残っているチャレンジについていくつか紹介できればと思います。
基盤システムの要件定義
いま構築しているプロダクトは約10個のECから利用される決済基盤です。
過去にも色々なプロダクトの開発に関わってきましたが、ラクスルほど大規模なプロダクトははじめてで基盤システムの開発と言えば、過去に2つのシステムから利用されるID基盤の開発にエンジニアとして少し関わったことはあったもののほぼはじめての経験でした。
これまでプロダクトマネージメントをする際は、ユーザーインタビューやデータ分析を通してユーザーのニーズやペインを理解することでプロダクトの方向性や仕様を決めていましたが、基盤システムとなるとエンドユーザーだけでなく、基盤システムを利用する社内の各プロダクトへの深い理解が必要になるので勝手が違ってきます。
決済基盤を利用する各ECの決済周りの仕様を把握した上で慎重に仕様を決めないと、これまでできていたことができなくなったり使い勝手が下がりユーザーの離脱につながってしまいます。価値向上のために多くのリソースを投下しているにも関わらずそうなっては本末転倒です。
また決済はしたら終わりではなく、その後キャンセルになることやトラブルによって返金したり、追加請求が発生することもあります。さらには決済された金額と決済代行業者から入金された金額を突合したり、最終的には正しく経理処理が行われる必要があります。
結果的に、各ECの仕様やオペレーション把握のために入社して3ヶ月の間に30名程度の方からヒアリングをさせていただきながら要件を固めていったのですが、これほどステークホルダーが多いシステムの要件定義ははじめてで、考慮すべきことがとても多いのが印象的でした。
ラクスル全体の理想を意識した概要設計
冒頭でも触れましたがラクスルはマイクロサービスで動いており、約10個のECに加え、特定の役割に特化した基盤的なシステムも複数存在します。今回はそこに決済基盤を新たに追加することになるのですが、システム間のAPIの設計を失敗すると密結合・低凝集なマイクロサービスができあがってしまい中長期にわたって大きな負債となり、事業の成長速度の悪化やエンジニアの開発体験の悪化を引き起こす懸念がありました。
とは言っても、私はラクスルに入りたてでしたので、既存システムや事業に関する解像度が浅く、1人で適切な設計をするのは現実的ではありませんでした。
そこで、CTOや社内のシニアエンジニアなど既存システムに詳しい方々の協力を得て、数ヶ月にわたって毎週設計レビュー会を実施させていただきました。最初に決済基盤で実現したいビジョンや要件を共有した上で論点の洗い出しを行い、その後はひとつひとつの論点に対する議論を行いました。
その際に意識したのが、現状からの積み上げで考えるのではなく、できる限り理想からの逆算で設計を行うということでした。現状からの積み上げで考える方が短期的には圧倒的に楽で速いのですが、それでは全体の理想からは遠ざかってしまう可能性があります。遠回りでもまずは目指すべき理想について関係者間で認識をあわせた上で、プロジェクトにかけられる期限や予算を考慮した落とし所を決めるというステップを意識することで、長期で見ると最短距離を進んでいるということを目指しました。
チーム一丸を目指した目標共有会
EMの仕事と言えば、チームメンバーの目標設定や評価をイメージする方も多いのではないでしょうか?ラクスルのEMもそのイメージに違わずチームメンバーの目標設定や評価を行います。
チームにおけるテクノロジーマネージメントやプロダクトマネージメントについては各EMの強みやチームメンバーの構成によって能力発揮の必要性は大きく異なっているように感じますが、ピープルマネージメントについてはもれなく一定レベルの能力発揮が必要とされていると感じます。
私が各チームメンバーの目標を設定して評価までには大まかに以下のようなことを行いました。
- 上長や共働するBizメンバーとチームのOKRを決める
- チームメンバーのWill(中長期の目指す姿やそのために獲得したい能力)を1on1でヒアリングする
- チームのOKR達成のためにやるべきことを分解する
- 分解したOKRの担当メンバーを現時点での適性とWillを考慮しながら割り当てる
- 4で割り当てた担当について各チームメンバーと1on1をしながら認識合わせをする
- チーム全員で目標共有会を開催して、全員が目標を達成するための作戦を立てる
- 6で立てた作戦がうまくいっているか月次で全員で振り返りを行い、作戦を調整する
- 週次で各チームメンバーと1on1を行い、目標達成への進捗や課題の確認をする
- 半期の終わりに振り返って評価を行う
色々とやっていますが、特に6の目標共有会と7の月次の振り返りが効果的だったと感じています。
過去のチームでは、これをやらなかったことで、お互いチャレンジしたいことが被ってしまったり、誰もやらずに放置されてしまうタスクが発生したりというような問題が発生することがあったのですが、これを実施することでチャレンジが被りそうな部分や放置されそうなタスクについて事前に調整を行うことができました。それ以外にも一人ひとりの目標達成に向けて他のメンバーにはどのような協力ができるかということも論点として議論をすることで、全員が自分の目標達成だけでなくチーム全員の目標達成を意識して一丸となって業務に取り組むことができていたと感じます。
今後のチャレンジ
今後チャレンジしたいことはたくさんあるのですが、1つだけピックアップしたいと思います。
ベトナムの開発チームとのコラボレーション強化
私のチームはこれまで日本語での会話や読み書きが可能なメンバーのみで開発を行っていました。今後さらに開発速度を上げたり、多くのことにチャレンジしていくには国内のエンジニアだけでは難しい状況のため、近々ベトナムの開発チームと共に開発していくことが決まっています。
ただ、これまで日本語を前提とした開発プロセスやドキュメンテーションを行っていたためベトナムメンバーが持っている能力を発揮できるようになるためには様々な改善が必要になることは明らかです。
私をはじめ、今いるチームメンバーは英語でのリアルタイムのコミュニケーションは難しいため、スクラムイベントを透明性を持って開催するにはどうすれば良いかというのも大きな課題です。
これらはぶつかるであろう課題のほんの一部で実際やってみるともっと色々と躓くのだと思います。一朝一夕で解決できない課題も多いため、目指す姿を明らかにしつつ時間をかけて一歩一歩根気強く取り組んでいくしかないと考えています。
ハードルは決して低くないですが、実現できた後の姿を想像するとワクワクするため、実現に向けて頑張っていきたいと思います!
最後に
今回は私がラクスルのEMになってからの半年を振り返ってみました。
ラクスルには良い意味で多くの取り組むべき課題があり、Willがあれば様々な機会提供が受けることができると強く感じています。
今後も定期的に振り返りをしつつ、初心を忘れずにチャレンジを続けていきたいと思います。